Abstract
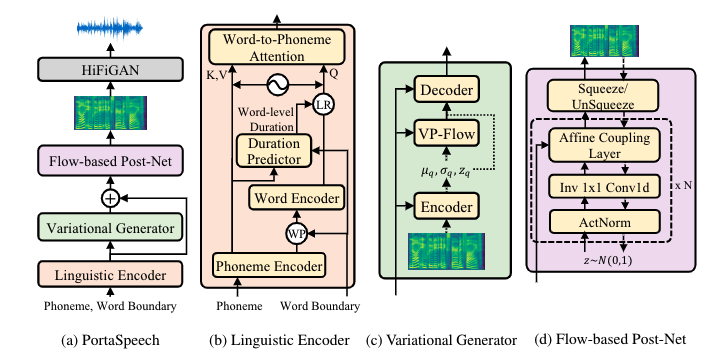
Non-autoregressive text-to-speech (NAR-TTS) models such as FastSpeech 2 and Glow-TTS can synthesize high-quality speech from the given text in parallel. After analyzing two kinds of generative NAR-TTS models (VAE and normalizing flow), we find that: VAE is good at capturing the long-range semantics features (e.g., prosody) even with small model size but suffers from blurry and unnatural results; and normalizing flow is good at reconstructing the frequency bin-wise details but performs poorly when the number of model parameters is limited. Inspired by these observations, to generate diverse speech with natural details and rich prosody using a lightweight architecture, we propose PortaSpeech, a portable and high-quality generative text-to-speech model. Specifically, 1) to model both the prosody and mel-spectrogram details accurately, we adopt a lightweight VAE with an enhanced prior followed by a flow-based post-net with strong conditional inputs as the main architecture. 2) To further compress the model size and memory footprint, we introduce the grouped parameter sharing mechanism to the affine coupling layers in the post-net. 3) To improve the expressiveness of synthesized speech and reduce the dependency on accurate fine-grained alignment between text and speech, we propose a linguistic encoder with mixture alignment combining hard inter-word alignment and soft intra-word alignment, which explicitly extracts word-level semantic information. Experimental results show that PortaSpeech outperforms other TTS models in both voice quality and prosody modeling in terms of subjective and objective evaluation metrics, and shows only a slight performance degradation when reducing the model parameters to 6.7M (about 4x model size and 3x runtime memory compression ratio compared with FastSpeech 2). Our extensive ablation studies demonstrate that each design in PortaSpeech is effective. d
Offical Code Github REPO
https://github.com/NATSpeech/NATSpeech
Audio Samples
- The essential point to be remembered is that the ornament, whatever it is, whether picture or pattern work, should form part of the page.
GT GT(voc.) Tacotron 2 TransformerTTS FastSpeech wav FastSpeech 2 Glow-TTS BVAE-TTS PortaSpeech (normal) PortaSpeech (small) wav - Most of caxtons own types are of an earlier character, though they also much resemble flemish or cologne letter.
GT GT(voc.) Tacotron 2 TransformerTTS FastSpeech wav FastSpeech 2 Glow-TTS BVAE-TTS PortaSpeech (normal) PortaSpeech (small) wav - Full details of the arrangements are to be found in mr. neilds state of prisons in england, scotland, and wales, published in eighteen twelve.
GT GT(voc.) Tacotron 2 TransformerTTS FastSpeech wav FastSpeech 2 Glow-TTS BVAE-TTS PortaSpeech (normal) PortaSpeech (small) wav